

今日头条分布式高并发
内容采集系统项目
今日头条内容智能识别
系统项目
CoolNiu商城实时数仓
系统项目




大数据已纳入国家十四五规划。大数据在健康医疗、智慧城市、互联网、电子商务等行业加速发展,人才缺口达100万+。

大数据人才可从事大数据开发、大数据仓储、大数据挖掘、深度学习、人工智能等岗位,岗位含金量高。

2021年下半年大数据领域企业平均薪资29000+,行业岗位薪资且无上限。

 技术大牛画图写算法
技术大牛画图写算法
 建集群比赛
建集群比赛
 技术PK赛
技术PK赛
 项目PK赛
项目PK赛
 虚拟机算力不足
虚拟机算力不足
 云计算价格昂贵
云计算价格昂贵
 物理集群算力自由
物理集群算力自由
 节省时间
节省时间
 安全放心
安全放心
 华为云精英服务商
华为云精英服务商
 华为大数据HCIP认证
华为大数据HCIP认证



CDP7.1.5、java1.8、shell、Hadoop3.1、kettle、mysql、hive3.1.3、hbase2.2.3、es7.6.2、kylin、kerberos、ranger2.0、sqoop1.4.7、Zookeeper3.5、flume1.9.0、impala3.4、airflow2.0.1、kudu1.12、hue4.5、jdbc、superset1.0.
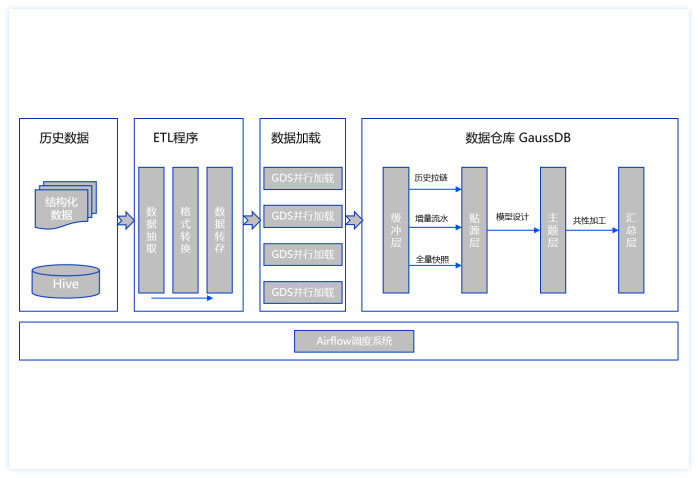
CoolNiu商城行为日志、业务日志与实体表作为数据源;经过ETL加工与数据抽取后入仓,数仓采用hive+kudu混合模式,支持高吞吐与随机读写需求,数据仓库进行技术缓冲层ITL、贴源模型层IOL逻辑加工处理,主体模型层IML划分,共性加工层ICL加工,应用集市层IDL
对外供数;数据集市对接报表系统;kylin对接数据仓库,联机分析处理,实现即席查询,毫秒级响应;hbase存储用户标签数据,结合es二级索引对外提供组合查询,实现亿级数据毫秒级查询响应;airflow实现T+N任务调度。
今日头条分布式高并发
内容采集系统项目
今日头条内容智能识别
系统项目
CoolNiu商城实时数仓
系统项目

MPP架构-历史数据迁移项目
NLP自然语言处理系统项目
巨量数据采集引擎项目
SNS社交网络实时数仓系统项目
大数据云服务平台
海量历史数据高速查询项目
湖仓一体化项目
无大数据工作经验
无大数据课程研发能力
课时80%为Java开发
实训项目少
实训环境虚拟机
就业较难保证
大数据岗位难匹配
成长空间有限

金山软件大数据总监
金山云大数据架构师
华为大数据架构师
大数据课程已迭代到8.0
课时100%为大数据开发
实训项目紧跟大数据前沿技术
真正的企业级物理集群服务器
名企内推、合作企业直推
所学技术扎实过硬,企
业好评度高
项目满足企业需求,薪
资高,发展机会大


Java基本语法
流程控制语句
数组
面向对象
常用工具类
集合
IO流
多线程
网络编程
正则、反射、XML
IDEA常用设置、常用快捷键
代码自动格式化
自定义模板
Git集成
Lambda表达式
StreamAPI
Optional加强
接口的私有化
构造器引用
类型推断
堆栈结构
单向循环链表
双向非循环链表
双向循环链表
有序树
无序树
二叉树
红黑树
插入排序
冒泡排序
选择排序
快速排序
归并排序
二分查找
穷举算法
贪心算法
单线程WordCount
多线程WordCount
多进程网络通信
多机分布式WordCount
本阶段主要目的,让零基础小白从Java过渡到大数据做好前置准备,不仅可以掌握Java的常见知识外,还重点解了面向对象抽象思维、集合源码、数据结构,逐步提高小白由浅入深的学习能力,此外还可以从分布式运算原理案例入手让大家为大数据框架学习打好基础。
数据库三范式
事务隔离
DML语言、DDL语言、DCL语言
Group查询、Join查询、子查询、Union查询
Mysql数据库、表、视图
Mysql索引、分页、SQL优化技巧
MySQL存储过程
慢查询分析
使用JDBC完成数据库增删改查操作
JDBC的批量查询与插入
数据库连接池详解
Druid连接池的优化
SecureCRT使用
Linux权限管理
Shell基本命令
文档目录管理
用户与用户组管理
进程管理
软件管理
shell编程
Zookeeper详解、数据存储结构
选举机制
分布式锁实现
Zookeeper容错恢复
Hadoop企业级集群服务器规划
Hadoop集群硬盘与网络性能调优
源码编译
HDFS底层详解
HDFS的HA高可用详解
HDFS的常用命令
跨集群数据迁移
LZO、SNAPPY、GZIP文件压缩格式
Yarn底层详解、Yarn的HA高可用详解
资源调度器热加载
MapReduce案例详解
MapReduce调优
Combiner、Conunter组件详解
分布式缓存应用
MapReduce源码剖析
MapReduce任务工作链
Hive架构原理
Hive元库类型
Hive元库类型高可用
Hive的DML数据操作
Hive企业级调优
Hive分区与分桶
ORC、AVRO、PARQUET格式对比
Hive开发环境调试模式
HIve常用函数
HIve自定义函数企业级部署
本阶段主要目的,从Mysql -> Hadoop -> MapReduce -> Hive的学习过程,让学员理解小数据处理和大数据处理的区别,单点运算与分布式运算的区别,从而深入理解大数据分布式运算的优缺点。并以Hadoop框架为中心提高学员的实操能力,以Hive为中心提高学生SQL能力,为后面的数仓课程打好基础。
主流大数据平台CDH、CDP、TDH、FI HD、FI MRS性能对比
CDH、CDP大数据平台搭建
Kerberos安全认证详解
Ranger服务集成
数据仓库各领域应用
数据仓库分层设计
数据仓库分层设计
数据仓库存储策略
Hbase各组件详解
分布式数据库特点、列式存储特点、nosql数据库与关系数据库区别
Hbase集群模式安装、Hbase的yarn模式安装
Hbase的企业级集群配置
Hbase的企业级集群配置
Hbase的shell操作
Hive外表加载数据到Hbase,Hive卸载Hbase数据
Hbase读写风暴优化
Phoenix安装配置
Phoenix查询原理
Phoenix与hbase如何结合使用
DDL与DML支持、事务支持
JDBC驱动嵌入讲解
Phoenix优缺点
Lily Hbase Indexer架构
Lily Hbase Indexer实现Solr二级索引
批量与准实时建立Hbase数据Solr索引
Solr的Morphline任务
Solr webui使用
Hue中使用Solr
倒排索引原理
分布式搜索引擎
Kibana集成
Logstash集成
IK分词器集成
创建索引、管理索引、管理副本、管理分片
ES与Hadoop数据同步
Java操作ES
Impala原理
数据类型
存储类型
常用函数实操
性能调优实操
操作Hbase实操
kudu架构
Table分区策略
Kudu底层数据模型
Kudu随机读写
读写性能对比
Java api操作不同数据刷新策略
Kylin原理
OLAP概述
Kylin安装部署
Cube设计
预计算实操
对接报表系统实操
Kettle原理、Kettle组件特性
Kettle数据转换实操
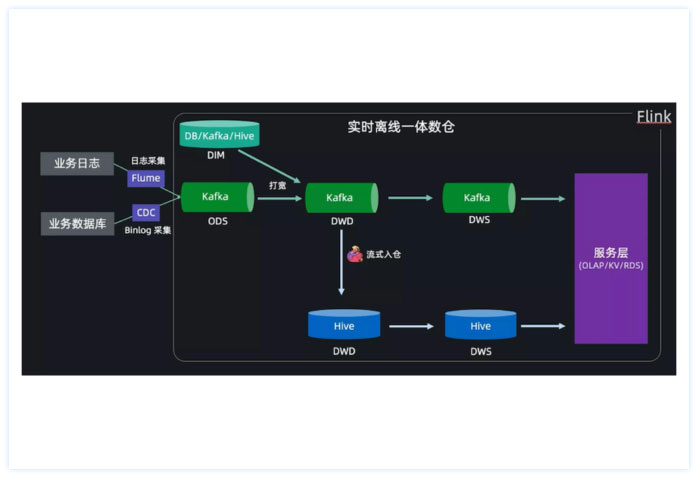
Flume框架介绍
Flume数据简单清洗
Source、Channel、Sink讲解
NetCat源、Spooling Directory源、Exec源、Avro源
原理、适用场景、split-by参数配置、num-mappers配置
设置input、设置output、设置map、设置task number、工作流程
操作mysql、hive
关系型数据库数据导入HDFS、增量抽取数据到HDFS
Airflow调度
DolphinScheduler调度
国产化数据库兴起及MPP架构热度
GaussDB与其他MPP数据库性能对比
GaussDB与hadoop的对比
GaussDB物理架构、集群逻辑部署
GaussDB行存储、列存储、混合存储
GaussDB数据类型
gsql客户端
DDL语法实操、DML语法实操、DCL语法实操
GaussDB分布键原理、GaussDB分布键设计策
GaussDB复制表与分布表原理
GaussDB分区剪枝原理、GaussDB数据迁移方式
GaussDB Roach容灾原理
GaussDB分布式执行计划原理
GaussDB函数和操作符
GaussDB存储过程
存储过程实操、GaussDB调优实操
本阶段主要目的,结合企业案例深入理解数据治理的主要方法,并使用工具化方式让大数据的计算与存储变的简单高效,不仅查的快,算的也容易,在此阶段学员即可掌握进入大数据行业的技能,可选择以数仓工程师方式就业,或者为更高级的大数据开发打好基础。
Scala与JVM的关系、Scala与Java的对比、Scala与Python的对比
Windows的Scala安装、Linux的Scala安装
使用Maven管理Scala、Scala的SDK开发配置
Scala基础语法
高阶函数、柯里化、隐式转换
多线程与网络编程
Spark介绍
集群安装、Yarn模式集群使用
RDD原理
Spark常用Transformations算子
Spark常用Actions算子
Spark背压原理
Shuffle优化
算子调优
内存调优
Spark-core
Spark-sql
Spark操作hbase
Spark-streaming
Receive流与Direct流对比
集群安装
Consumer、Producer、Broker、Topic、Partition组件原理
Kafka的Java api操作
自动管理Offset、手机管理Offset
Kafka调优
Spark-streaming操作Offset到Zookeeper/Redis
Flink生态、Flink的发展与未来趋势
Flink的反压机制、Flink的DataFlow原理、Flink的状态编程
Local模式安装、Standalone模式安装、HA模式安装、yarn模式安装
TaskManger原理、JobManagers原理、Client原理
Scala/Java开发环境搭建
SourceFunction、ProcessFunction、SinkFunction、RichFunction、ProcessFunction
Operator算子编程
Connect、Union、KeyBy实现数据Join
State作用与原理、分布式Checkpoint原理、SavePoint原理
EventTime、IngestTime、ProcessingTime区别,Watermark原理
统计Windows、滚动Window、滑动Window、事件Window
TimeService实现自定义窗口
Flink-sql、CEP、异步IO
使用Flink CDC同步Mysql数据
Python脚本语言运行原理、与Java/Scala区别
Python基础语法、PyCharm开发工作安装与使用
Pip包管理
Python的分布式框架编写
Redis介绍、Redis应用场景
Redis单机模式、一致性hash原理、Redis集群模式
redis容灾、redis主备复制方案、redis读写分离方案
python操作redis、java操作redis、scala操作redis
ClickHouse的安装部署
读写机制
数据类型
执行引擎
微服务接口
SpringCloud负载均衡
本阶段主要目的,深入理解大数据生态不仅要查的快而且要算的快,并结合软件工程中的设计模式,让学员深入理解软件架构的组成为以后的职业生涯打好基础,在原有第三阶段学习具备就业能力的基础上提高学员的薪资水平。
本阶段主要目的,本阶段根据小、中、大的企业使用大数据的场景,全方位设计大数据项目,以项目为中心,以企业级大数据集群为平台,让学员迅速完成实战经验积累,加强对各大数据框架的认识,让学生有能力应对市面上各种类型公司的大数据需求。
本阶段主要目的,根据学员自身特点优化面试技巧,提炼面式过程中项目的技术关键点,并给予未来职业发展的建议,让学员在求职过程中过好面试关,工作过程中少踩坑,让学员有足够的信心应对未来的大数据技术之路。






![]() 电话:18613807937
电话:18613807937
![]() 地址:北京市大兴区芦花路1号院时代•智谷A座501
地址:北京市大兴区芦花路1号院时代•智谷A座501
Copyright 2001-2022 海牛大数据 - 北京阳光海牛科技有限公司 版权所有
京ICP备17041118号 在线咨询
在线咨询
现在就与学习导师聊一聊

18613807937
